resultMap 是 MyBatis 框架中常用的特性,主要用于映射结果。
resutMap元素是 MyBatis 中最重要最强大的元素。它可以让你从 90% 的 JDBC ResutSets数据提取代码中解放出来,并在一些情形下允许你做一些JDBC不支持的事情。实际上,在对复杂语句进行联合映射的时候,它很可能可以代替数千行的同等功能的代码。ResutMap
的设计思想是,简单的语句不需要明确的结果映射,而复杂一点的语句只需要描述它们的
关系就行了。
通过 resultMap 和自动映射,可以让 MyBatis 帮助我们完成ResultSet → Object 的映射,这将会大大提高了开发效率。
解析过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
| // -☆- XMLMapperBuilder
private void resultMapElements(List<XNode> list) throws Exception {
// 遍历 <resultMap> 节点列表
//基本上就是循环把resultMap加入到Configuration里去,保持2份,一份缩略,一分全名
for (XNode resultMapNode : list) {
try {
// 解析 resultMap 节点
resultMapElement(resultMapNode);
} catch (IncompleteElementException e) {
}
}
}
private ResultMap resultMapElement(XNode resultMapNode) throws Exception {
// 调用重载方法
return resultMapElement(resultMapNode,
Collections.<ResultMapping>emptyList());
}
private ResultMap resultMapElement(XNode resultMapNode,
List<ResultMapping> additionalResultMappings) throws Exception {
ErrorContext.instance().activity("processing " +
resultMapNode.getValueBasedIdentifier());
// 获取 id 和 type 属性
String id = resultMapNode.getStringAttribute("id",
resultMapNode.getValueBasedIdentifier());
String type = resultMapNode.getStringAttribute("type",
resultMapNode.getStringAttribute("ofType",
resultMapNode.getStringAttribute("resultType",
resultMapNode.getStringAttribute("javaType"))));
// 获取 extends 和 autoMapping
String extend = resultMapNode.getStringAttribute("extends");
Boolean autoMapping = resultMapNode.getBooleanAttribute("autoMapping");
// 解析 type 属性对应的类型
Class<?> typeClass = resolveClass(type);
Discriminator discriminator = null;
List<ResultMapping> resultMappings = new ArrayList<ResultMapping>();
resultMappings.addAll(additionalResultMappings);
// 获取并遍历 <resultMap> 的子节点列表
List<XNode> resultChildren = resultMapNode.getChildren();
for (XNode resultChild : resultChildren) {
if ("constructor".equals(resultChild.getName())) {
// 解析 constructor 节点,并生成相应的 ResultMapping
processConstructorElement(resultChild, typeClass, resultMappings);
} else if ("discriminator".equals(resultChild.getName())) {
// 解析 discriminator 节点
discriminator = processDiscriminatorElement(
resultChild, typeClass, resultMappings);
} else {
List<ResultFlag> flags = new ArrayList<ResultFlag>();
if ("id".equals(resultChild.getName())) {
// 添加 ID 到 flags 集合中
flags.add(ResultFlag.ID);
}
// 解析 id 和 property 节点,并生成相应的 ResultMapping
resultMappings.add(buildResultMappingFromContext(
resultChild, typeClass, flags));
}
}
ResultMapResolver resultMapResolver = new ResultMapResolver(
builderAssistant, id, typeClass, extend, discriminator,
resultMappings, autoMapping);
try {
// 根据前面获取到的信息构建 ResultMap 对象
return resultMapResolver.resolve();
} catch (IncompleteElementException e) {
/*
* 如果发生 IncompleteElementException 异常,
* 这里将 resultMapResolver 添加到 incompleteResultMaps 集合中
*/
configuration.addIncompleteResultMap(resultMapResolver);
throw e;
}
}
|
上面的代码比较多,看起来有点复杂,这里总结一下:
- 获取节点的各种属性
- 遍历的子节点,并根据子节点名称执行相应的解析逻辑
- 构建 ResultMap 对象
- 若构建过程中发生异常,则将 resultMapResolver 添加到incompleteResultMaps 集合中
解析id和result节点
子节点和都是常规配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| private ResultMapping buildResultMappingFromContext(XNode context, Class<?>
resultType, List<ResultFlag> flags) throws Exception {
String property;
// 根据节点类型获取 name 或 property 属性
if (flags.contains(ResultFlag.CONSTRUCTOR)) {
property = context.getStringAttribute("name");
} else {
property = context.getStringAttribute("property");
}
// 获取其他各种属性
String column = context.getStringAttribute("column");
String javaType = context.getStringAttribute("javaType");
String jdbcType = context.getStringAttribute("jdbcType");
String nestedSelect = context.getStringAttribute("select");
// 解析 resultMap 属性,该属性出现在 <association> 和 <collection> 节点中
// 若这两个节点不包含 resultMap 属性,则调用 processNestedResultMappings 方法
// 解析嵌套 resultMap。
String nestedResultMap = context.getStringAttribute("resultMap",
processNestedResultMappings(context, Collections.<ResultMapping>emptyList()));
String notNullColumn = context.getStringAttribute("notNullColumn");
String columnPrefix = context.getStringAttribute("columnPrefix");
String typeHandler = context.getStringAttribute("typeHandler");
String resultSet = context.getStringAttribute("resultSet");
String foreignColumn = context.getStringAttribute("foreignColumn");
boolean lazy = "lazy".equals(context.getStringAttribute("fetchType",
configuration.isLazyLoadingEnabled() ? "lazy" : "eager"));
// 解析 javaType、typeHandler 的类型以及枚举类型 JdbcType
Class<?> javaTypeClass = resolveClass(javaType);
Class<? extends TypeHandler<?>> typeHandlerClass = (Class<? extends TypeHandler<?>>) resolveClass(typeHandler);
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
// 构建 ResultMapping 对象
return builderAssistant.buildResultMapping(
resultType, property, column, javaTypeClass, jdbcTypeEnum,
nestedSelect, nestedResultMap, notNullColumn, columnPrefix,
typeHandlerClass, flags, resultSet, foreignColumn, lazy);
}
|
主要用于获取和节点的属性,其中,resultMap属性的解析过程要相对复杂一些。该属性存在于和节点中。该节点有两种配置方式:
- 通过 resultMap 属性引用其他的节点
1
2
3
4
5
6
7
8
9
10
11
12
| <resultMap id="articleResult" type="Article">
<id property="id" column="id"/>
<result property="title" column="article_title"/>
<association property="article_author" column="article_author_id"
resultMap="authorResult"/>
</resultMap>
<resultMap id="authorResult" type="Author">
<id property="id" column="author_id"/>
<result property="name" column="author_name"/>
</resultMap>
|
- 采取 resultMap 嵌套的方式进行配置
1
2
3
4
5
6
7
8
| <resultMap id="articleResult" type="Article">
<id property="id" column="id"/>
<result property="title" column="article_title"/>
<association property="article_author" javaType="Author">
<id property="id" column="author_id"/>
<result property="name" column="author_name"/>
</association>
</resultMap>
|
的子节点解析过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| private String processNestedResultMappings(XNode context,
List<ResultMapping> resultMappings) throws Exception {
// 判断节点名称
if ("association".equals(context.getName())
|| "collection".equals(context.getName())
|| "case".equals(context.getName())) {
if (context.getStringAttribute("select") == null) {
// resultMapElement 是解析 ResultMap 入口方法
ResultMap resultMap = resultMapElement(context, resultMappings);
// 返回 resultMap id
return resultMap.getId();
}
}
return null;
}
|
的子节点由 resultMapElement 方法解析成 ResultMap,并在最后返回resultMap.id。对于节点,id 的值配置在该节点的 id 属性中。
节点无法配置 id 属性,那么该 id 如何产生的呢?在 XNode 类的 getValueBasedIdentifier 方法中,解析后的ID:
1
| id = mapper_resultMap[articleResult]_association[article_author]
|
ResultMapping 的构建过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| public ResultMapping buildResultMapping(Class<?> resultType,
String property, String column, Class<?> javaType,
JdbcType jdbcType, String nestedSelect, String nestedResultMap,
String notNullColumn, String columnPrefix,
Class<? extends TypeHandler<?>> typeHandler,List<ResultFlag> flags,
String resultSet, String foreignColumn, boolean lazy) {
// 若 javaType 为空,这里根据 property 的属性进行解析。关于下面方法中的参数,
// 这里说明一下:
// - resultType:即 <resultMap type="xxx"/> 中的 type 属性
// - property:即 <result property="xxx"/> 中的 property 属性
Class<?> javaTypeClass =
resolveResultJavaType(resultType, property, javaType);
// 解析 TypeHandler
TypeHandler<?> typeHandlerInstance =
resolveTypeHandler(javaTypeClass, typeHandler);
// 解析 column = {property1=column1, property2=column2} 的情况,
// 这里会将 column 拆分成多个 ResultMapping
List<ResultMapping> composites = parseCompositeColumnName(column);
// 通过建造模式构建 ResultMapping
return new ResultMapping
.Builder(configuration, property, column, javaTypeClass)
.jdbcType(jdbcType)
.nestedQueryId(applyCurrentNamespace(nestedSelect, true))
.nestedResultMapId(applyCurrentNamespace(nestedResultMap, true))
.resultSet(resultSet).typeHandler(typeHandlerInstance)
.flags(flags == null ? new ArrayList<ResultFlag>() : flags)
.composites(composites)
.notNullColumns(parseMultipleColumnNames(notNullColumn))
.columnPrefix(columnPrefix).foreignColumn(foreignColumn)
.lazy(lazy).build();
}
// -☆- ResultMapping.Builder
public ResultMapping build() {
// 将 flags 和 composites 两个集合变为不可修改集合
resultMapping.flags = Collections.unmodifiableList(resultMapping.flags);
resultMapping.composites =
Collections.unmodifiableList(resultMapping.composites);
// 从 TypeHandlerRegistry 中获取相应 TypeHandler
resolveTypeHandler();
validate();
return resultMapping;
}
|
ResultMapping 的构建过程不是很复杂,首先是解析 javaType 类型,并创建 typeHandler实例。然后处理复合 column。最后通过建造器构建 ResultMapping 实例。
解析节点
一般情况下,我们所定义的实体类都是简单的 Java 对象,即 POJO。这种对象包含一些私有属性和相应的 getter/setter方法,通常这种POJO可以满足大部分需求。但如果你想使用不可变类存储查询结果,则就需要做一些改动。比如把POJO的setter方法移除,增加构造方法用于初始化成员变量。
对于这种不可变的Java类,需要通过带有参数的构造方法进行初始化(反射也可以达到同样目的)
实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public class Article {
// ...
public Article(Integer id, String title, String content) {
this.id = id;
this.title = title;
this.content = content;
}
}
<constructor>
<idArg column="id" name="id"/>
<arg column="title" name="title"/>
<arg column="content" name="content"/>
</constructor>
|
constructor 节点的解析过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| private void processConstructorElement(XNode resultChild,
Class<?> resultType, List<ResultMapping> resultMappings)
throws Exception {
// 获取子节点列表
List<XNode> argChildren = resultChild.getChildren();
for (XNode argChild : argChildren) {
List<ResultFlag> flags = new ArrayList<ResultFlag>();
// 向 flags 中添加 CONSTRUCTOR 标志
flags.add(ResultFlag.CONSTRUCTOR);
if ("idArg".equals(argChild.getName())) {
// 向 flags 中添加 ID 标志
flags.add(ResultFlag.ID);
}
// 构建 ResultMapping,上一节已经分析过
resultMappings.add(
buildResultMappingFromContext(argChild, resultType, flags));
}
}
|
首先是获取并遍历子节点列表,然后为每个子节点创建 flags集合,并添加 CONSTRUCTOR 标志。对于 idArg 节点,额外添加 ID 标志。最后一步则是构建 ResultMapping
ResultMap 对象构建过程分析
通过前面的分析,我们可知,等节点最终都被解析成了ResultMapping。在得到这些 ResultMapping 后,紧接着要做的事情是构建 ResultMap。
ResultMap 的构建逻辑分装在 ResultMapResolver 的 resolve 方法中
1
2
3
4
5
| // -☆- ResultMapResolver
public ResultMap resolve() {
return assistant.addResultMap(this.id, this.type, this.extend,
this.discriminator, this.resultMappings, this.autoMapping);
}
|
任务委托给了 MapperBuilderAssistant的addResultMap
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| // -☆- MapperBuilderAssistant
public ResultMap addResultMap(
String id, Class<?> type, String extend, Discriminator discriminator,
List<ResultMapping> resultMappings, Boolean autoMapping) {
// 为 ResultMap 的 id 和 extend 属性值拼接命名空间
id = applyCurrentNamespace(id, false);
extend = applyCurrentNamespace(extend, true);
if (extend != null) {
if (!configuration.hasResultMap(extend)) {
throw new IncompleteElementException("……");
}
ResultMap resultMap = configuration.getResultMap(extend);
List<ResultMapping> extendedResultMappings = new
ArrayList<ResultMapping>(resultMap.getResultMappings());
// 为拓展 ResultMappings 取出重复项
extendedResultMappings.removeAll(resultMappings);
boolean declaresConstructor = false;
// 检测当前 resultMappings 集合中是否包��� CONSTRUCTOR 标志的元素
for (ResultMapping resultMapping : resultMappings) {
if (resultMapping.getFlags().contains(ResultFlag.CONSTRUCTOR)) {
declaresConstructor = true;
break;
}
}
// 如果当前 <resultMap> 节点中包含 <constructor> 子节点,
// 则将拓展 ResultMapping 集合中的包含 CONSTRUCTOR 标志的元素移除
if (declaresConstructor) {
Iterator<ResultMapping> extendedResultMappingsIter =
extendedResultMappings.iterator();
while (extendedResultMappingsIter.hasNext()) {
if (extendedResultMappingsIter.next().getFlags()
.contains(ResultFlag.CONSTRUCTOR)) {
extendedResultMappingsIter.remove();
}
}
}
// 将扩展 resultMappings 集合合并到当前 resultMappings 集合中
resultMappings.addAll(extendedResultMappings);
}
// 构建 ResultMap
ResultMap resultMap = new ResultMap
.Builder(configuration, id, type, resultMappings, autoMapping) .discriminator(discriminator) .build();
configuration.addResultMap(resultMap);
return resultMap;
}
|
上面的方法主要用于处理 resultMap 节点的 extend 属性,extend 不为空的话,这里将当前 resultMappings 集合和扩展 resultMappings 集合合二为一。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
| // -☆- ResultMap
public ResultMap build() {
if (resultMap.id == null) {
throw new IllegalArgumentException("ResultMaps must have an id");
}
resultMap.mappedColumns = new HashSet<String>();
resultMap.mappedProperties = new HashSet<String>();
resultMap.idResultMappings = new ArrayList<ResultMapping>();
resultMap.constructorResultMappings = new ArrayList<ResultMapping>();
resultMap.propertyResultMappings = new ArrayList<ResultMapping>();
final List<String> constructorArgNames = new ArrayList<String>();
for (ResultMapping resultMapping : resultMap.resultMappings) {
// 检测 <association> 或 <collection> 节点
// 是否包含 select 和 resultMap 属性
resultMap.hasNestedQueries = resultMap.hasNestedQueries ||
resultMapping.getNestedQueryId() != null;
resultMap.hasNestedResultMaps = resultMap.hasNestedResultMaps ||
(resultMapping.getNestedResultMapId() != null &&
resultMapping.getResultSet() == null);
final String column = resultMapping.getColumn();
if (column != null) {
// 将 colum 转换成大写,并添加到 mappedColumns 集合中
resultMap.mappedColumns.add(column.toUpperCase(Locale.ENGLISH));
} else if (resultMapping.isCompositeResult()) {
for (ResultMapping compositeResultMapping :
resultMapping.getComposites()) {
final String compositeColumn =
compositeResultMapping.getColumn();
if (compositeColumn != null) {
resultMap.mappedColumns.add(
compositeColumn.toUpperCase(Locale.ENGLISH));
}
}
}
// 添加属性 property 到 mappedProperties 集合中
final String property = resultMapping.getProperty();
if (property != null) {
resultMap.mappedProperties.add(property);
}
// 检测当前 resultMapping 是否包含 CONSTRUCTOR 标志
if (resultMapping.getFlags().contains(ResultFlag.CONSTRUCTOR)) {
// 添加 resultMapping 到 constructorResultMappings 中
resultMap.constructorResultMappings.add(resultMapping);
// 添加属性(constructor 节点的 name 属性)到 constructorArgNames 中
if (resultMapping.getProperty() != null) {
constructorArgNames.add(resultMapping.getProperty());
}
} else {
// 添加 resultMapping 到 propertyResultMappings 中
resultMap.propertyResultMappings.add(resultMapping);
}
if (resultMapping.getFlags().contains(ResultFlag.ID)) {
// 添加 resultMapping 到 idResultMappings 中
resultMap.idResultMappings.add(resultMapping);
}
}
if (resultMap.idResultMappings.isEmpty()) {
resultMap.idResultMappings.addAll(resultMap.resultMappings);
}
if (!constructorArgNames.isEmpty()) {
// 获取构造方法参数列表,篇幅原因,这个方法不分析了
final List<String> actualArgNames =
argNamesOfMatchingConstructor(constructorArgNames);
if (actualArgNames == null) {
throw new BuilderException("……");
}
// 对 constructorResultMappings 按照构造方法参数列表的顺序进行排序
Collections.sort(resultMap.constructorResultMappings,
new Comparator<ResultMapping>() {
@Override
public int compare(ResultMapping o1, ResultMapping o2) {
int paramIdx1 = actualArgNames.indexOf(o1.getProperty());
int paramIdx2 = actualArgNames.indexOf(o2.getProperty());
return paramIdx1 - paramIdx2;
}
});
}
// 将以下这些集合变为不可修改集合
resultMap.resultMappings =
Collections.unmodifiableList(resultMap.resultMappings);
resultMap.idResultMappings =
Collections.unmodifiableList(resultMap.idResultMappings);
resultMap.constructorResultMappings =
Collections.unmodifiableList(resultMap.constructorResultMappings);
resultMap.propertyResultMappings =
Collections.unmodifiableList(resultMap.propertyResultMappings);
resultMap.mappedColumns =
Collections.unmodifiableSet(resultMap.mappedColumns);
return resultMap;
}
|
以上代码主要做的事情就是将ResultMapping实例及属性分别存储到不同的集合中,仅此而已。
ResultMap 中定义了五种不同的集合
| 集合名称 |
用途 |
| mappedColumns |
用于存储节点 column 属性 |
| mappedProperties |
用于存储和节点的 property 属性,或 和节点的 name 属性 |
| idResultMappings |
用于存储和节点对应的 ResultMapping 对象 |
| propertyResultMappings |
用于存 和节点对应的 ResultMapping 对象 |
| constructorResultMappings |
用于存储和节点对应的 ResultMapping 对象 |
测试流程
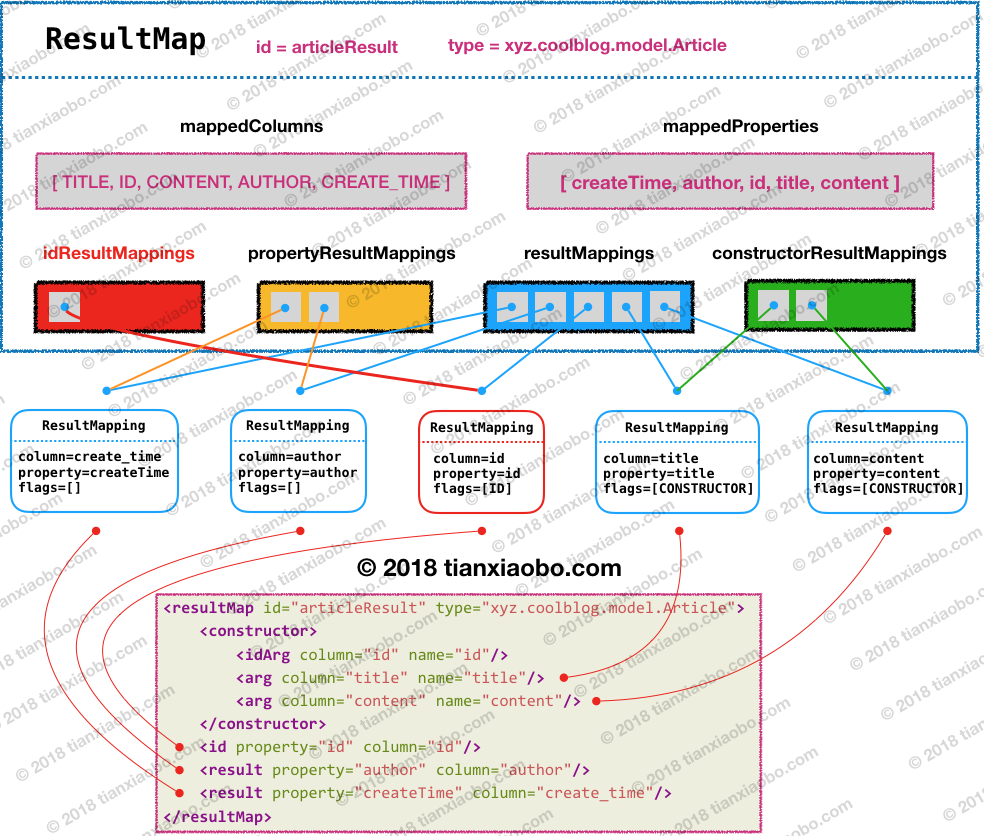
映射文件
1
2
3
4
5
6
7
8
9
10
11
12
| <mapper namespace="xyz.coolblog.chapter3.dao.ArticleDao">
<resultMap id="articleResult" type="xyz.coolblog.chapter3.model.Article">
<constructor>
<idArg column="id" name="id"/>
<arg column="title" name="title"/>
<arg column="content" name="content"/>
</constructor>
<id property="id" column="id"/>
<result property="author" column="author"/>
<result property="createTime" column="create_time"/>
</resultMap>
</mapper>
|
测试代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
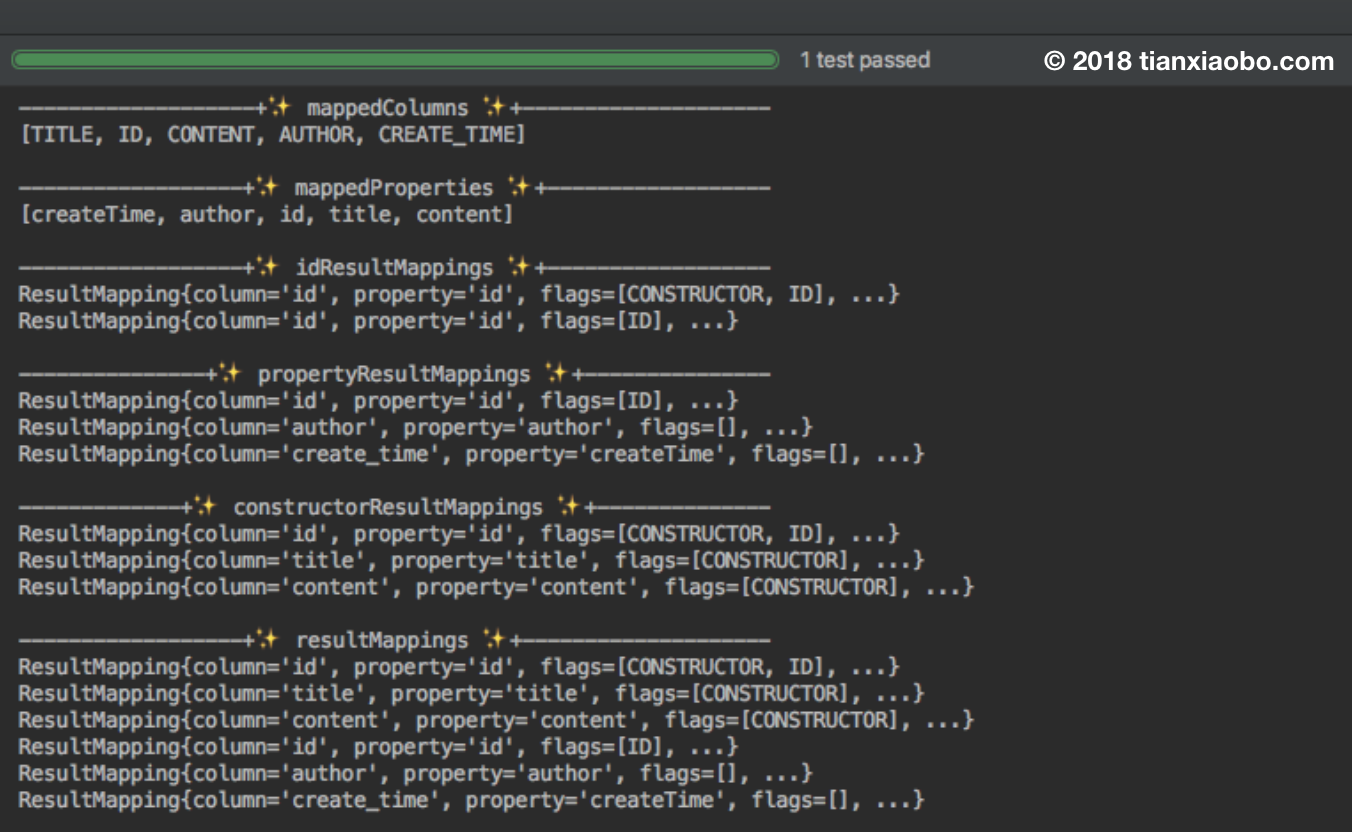
| public class ResultMapTest {
@Test
public void printResultMapInfo() throws Exception {
Configuration configuration = new Configuration();
String resource = "chapter3/mapper/ArticleMapper.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
XMLMapperBuilder builder = new XMLMapperBuilder(inputStream,
configuration, resource, configuration.getSqlFragments());
builder.parse();
ResultMap resultMap = configuration.getResultMap("articleResult");
System.out.println("\n----------+✨ mappedColumns ✨+-----------");
System.out.println(resultMap.getMappedColumns());
System.out.println("\n---------+✨ mappedProperties ✨+---------");
System.out.println(resultMap.getMappedProperties());
System.out.println("\n---------+✨ idResultMappings ✨+----------");
resultMap.getIdResultMappings().forEach(
rm -> System.out.println(simplify(rm)));
System.out.println("\n------+✨ propertyResultMappings ✨+-------");
resultMap.getPropertyResultMappings().forEach(
rm -> System.out.println(simplify(rm)));
System.out.println("\n----+✨ constructorResultMappings ✨+-----");
resultMap.getConstructorResultMappings().forEach(
rm -> System.out.println(simplify(rm)));
System.out.println("\n---------+✨ resultMappings ✨+-----------");
resultMap.getResultMappings().forEach(
rm -> System.out.println(simplify(rm)));
inputStream.close();
}
/** 简化 ResultMapping 输出结果 */
private String simplify(ResultMapping resultMapping) {
return String.format(
"ResultMapping{column='%s', property='%s', flags=%s, ...}",
resultMapping.getColumn(), resultMapping.getProperty(),
resultMapping.getFlags());
}
}
|
参照上面配置文件及输出的结果,把 ResultMap 的大致轮廓画出来